FlashDecoding 原理 | 深度学习算法
FlashDecoding 在 FlashAttention 2 的基础上针对 LLM 推理时的 decoding 步骤进行了进一步的性能优化,其计算结果仍然是严格对齐的。
背景
在 LLM 推理场景中,主要包含以下操作:
- linear projection:1、5
- attention:2、3、4
- feedforward network:6
LLM 推理时对 prompt 的处理过程称为 prefill phase,第二阶段预测过程称为 decode phase。这两个阶段的算子基本一致,主要区别在于是输入数据的形状。由于 decode phase 一次只处理一个 token,因此输入矩阵变成了一维矩阵(向量),如下图 decode phase 部分中和 KV cache 拼接的红色向量:
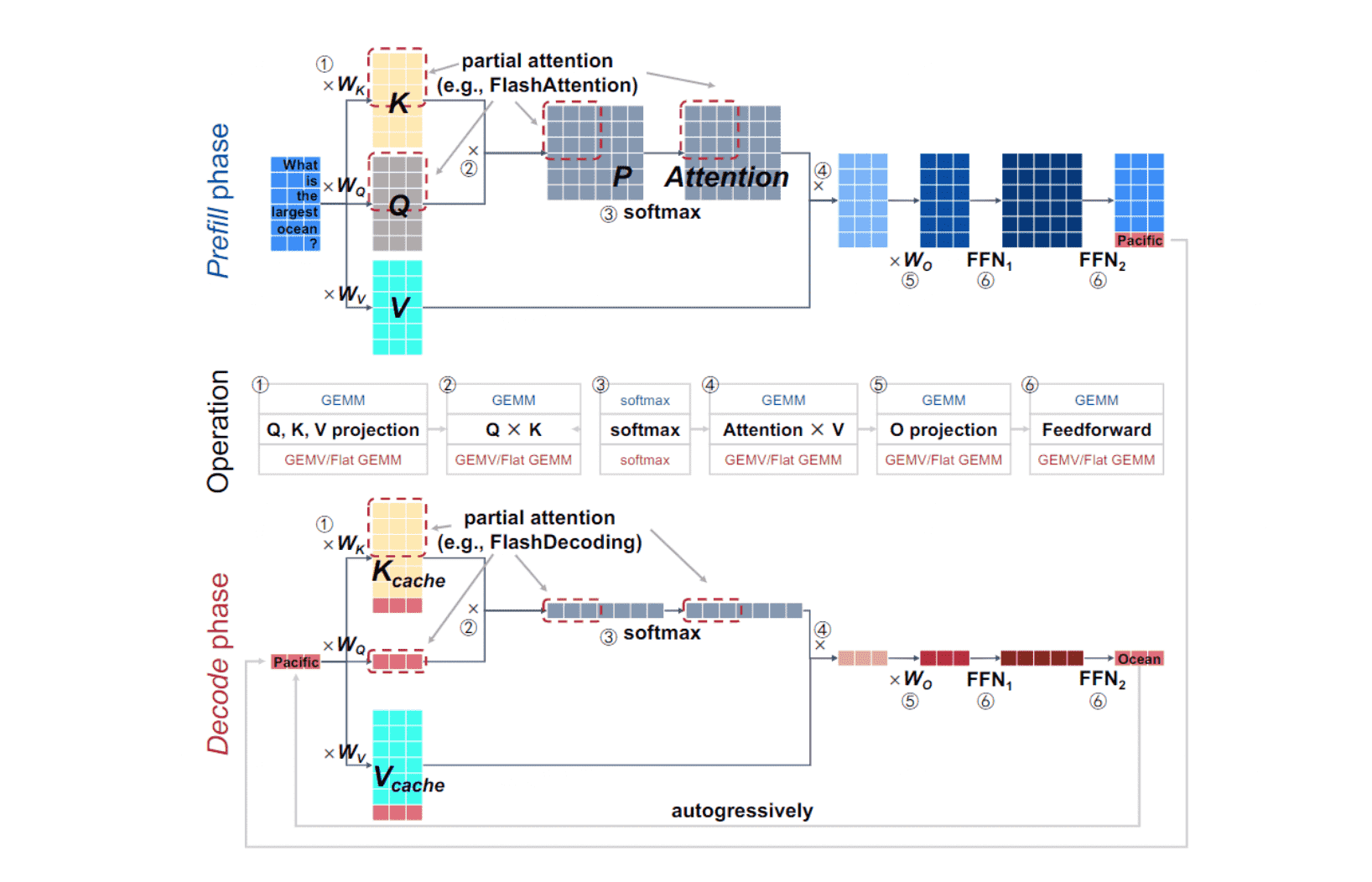
原理
正如上一篇博客中中所提到的,FlashAttention 2 通过在序列长度维度进行并行来缓解 batch size 比较小时并行化程度不高的问题。在 LLM decode 步骤中,batch size 直接降为 1,这进一步导致了 GPU 率下降。
FlashDecoding 通过对 FlashAttention 2 的内层循环进行并行拆分进一步提高了推理场景的并行化程度。
先来回顾一下 FlashAttention 2 的推理流程:
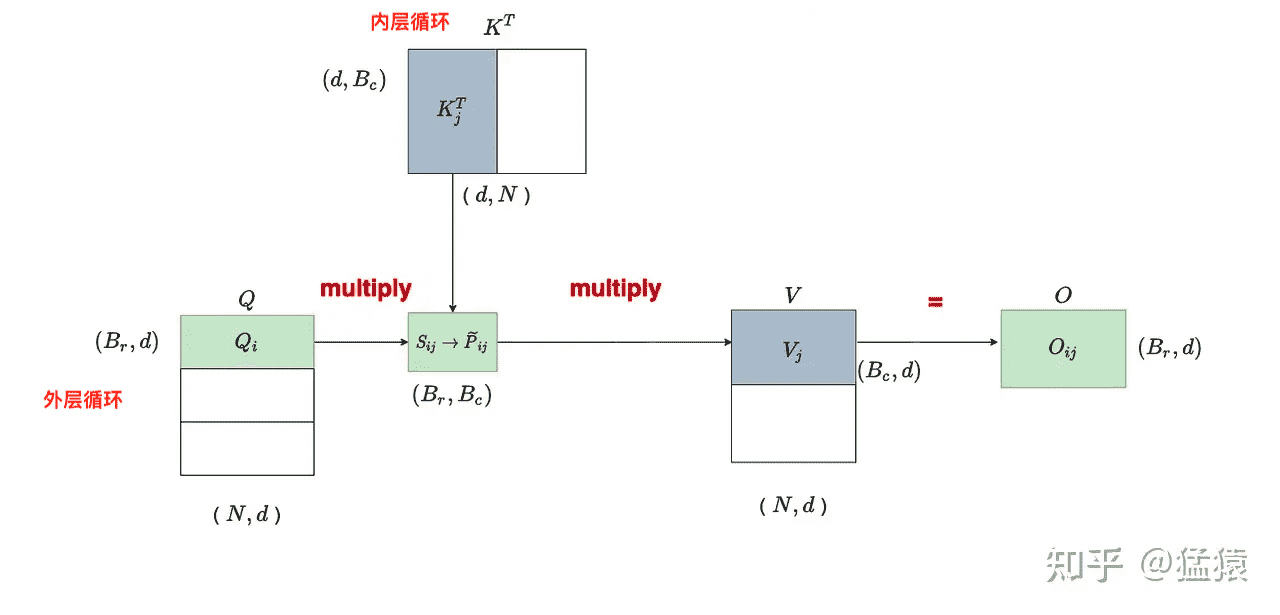
在 decode 步骤中,外层循环次数直接变为 1,只剩下串行的内层循环:

为了保证并行度,只能继续切分内层循环。但是内层循环需要做规约操作,不同 block 任务之间需要通信。因此,就有了下图的执行逻辑:
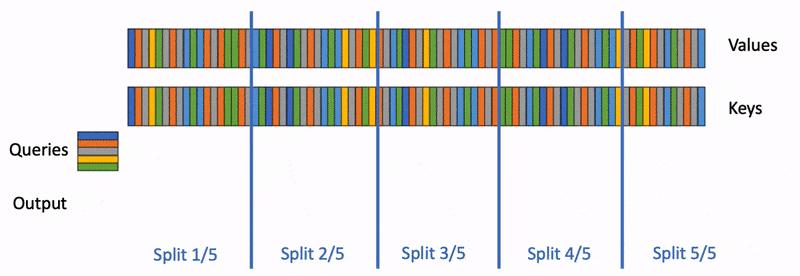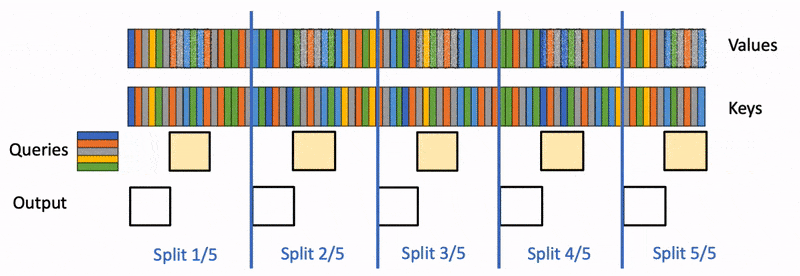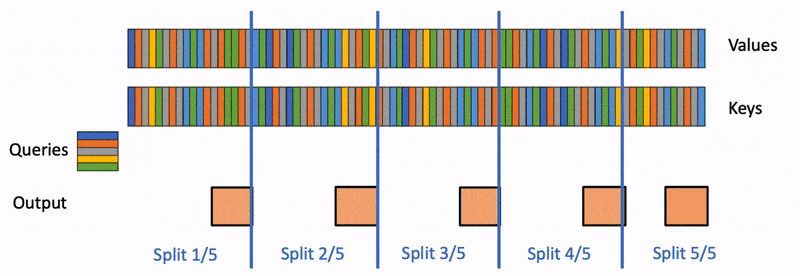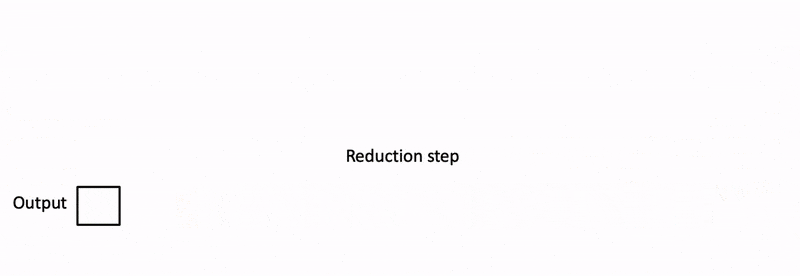
内层循环被分成 5 份,每一块被调度到一个 block 上计算局部结果,最后 5 个 block 还需要进行汇总得到最终结果。
参考
Flash-Decoding for long-context inference
FlashDecoding 原理 | 深度学习算法