本文对 Taichi 中的 codegen 部分源代码进行了解读。
version: 1.2.0
commit id: f189fd791
git repo: https://code.byted.org/UGC-SDK/Rosetta-taichi/tree/dev/v1.2.0
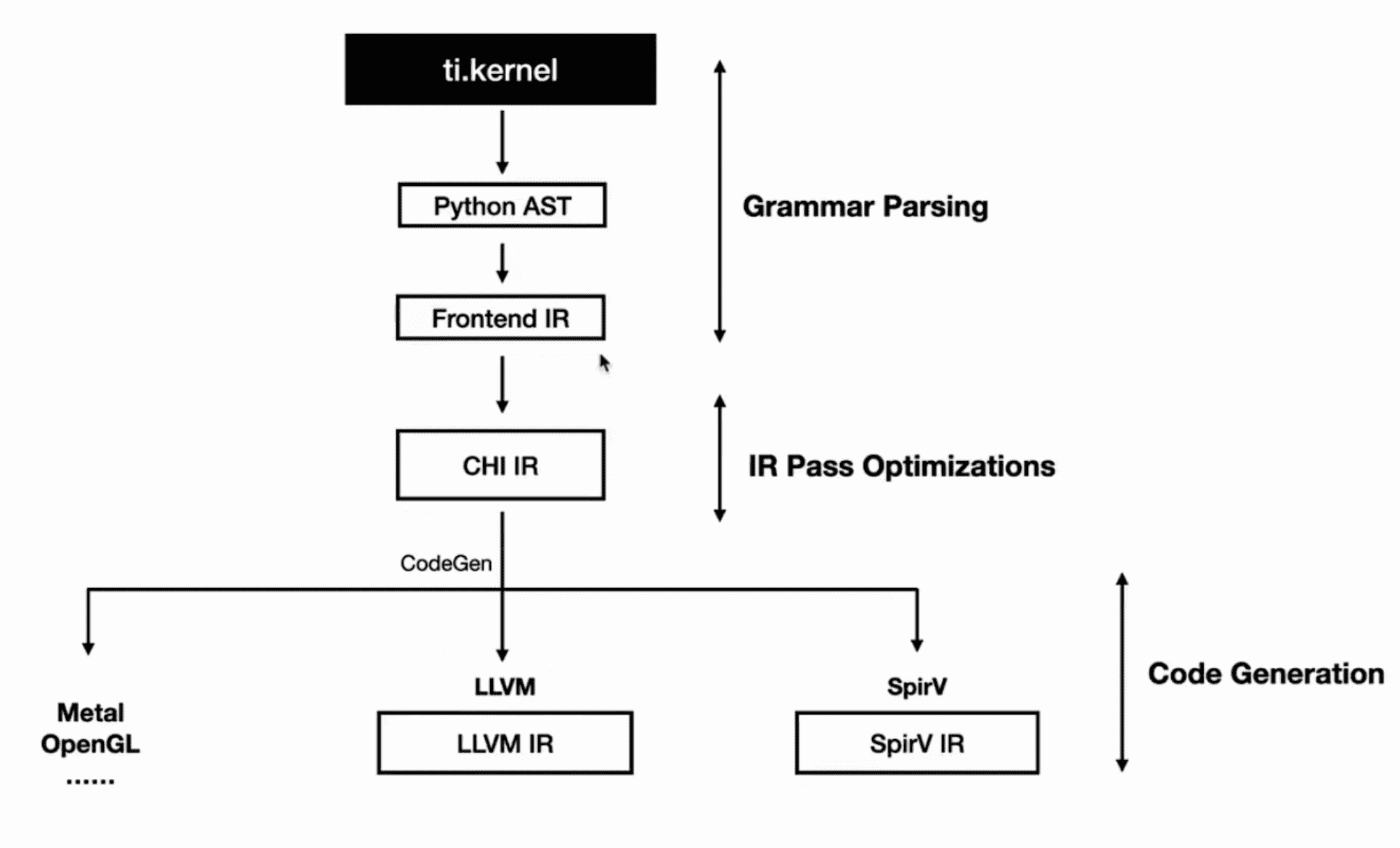
Overview 我们以一个简单的 demo 为例,从源码层面过一下整个代码生成的流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import taichi as titi.init(arch=ti.vulkan, print_ir=True ) nsize = 128 num_channels = 4 @ti.kernel def taichi_add ( in_ten: ti.types.rw_texture(num_dimensions=1 , num_channels=num_channels, channel_format=ti.u8, lod=0 ), out_ten: ti.types.rw_texture(num_dimensions=1 , num_channels=num_channels, channel_format=ti.u8, lod=0 ), nsize: ti.i32, addend: ti.i32, for i in ti.ndrange(nsize): in_num = in_ten.load(ti.Vector([i])) sum_num = in_num + ti.cast(addend, ti.f32) / 255.0 out_ten.store(ti.Vector([i]), sum_num) arg_0 = ti.graph.Arg(tag=ti.graph.ArgKind.RWTEXTURE, name="in_ten" , channel_format=ti.u8, shape=(nsize,), num_channels=num_channels) arg_1 = ti.graph.Arg(tag=ti.graph.ArgKind.RWTEXTURE, name="out_ten" , channel_format=ti.u8, shape=(nsize,), num_channels=num_channels) arg_2 = ti.graph.Arg(ti.graph.ArgKind.SCALAR, "nsize" , ti.i32) arg_3 = ti.graph.Arg(ti.graph.ArgKind.SCALAR, "addend" , ti.i32) g = ti.graph.GraphBuilder() g.dispatch(taichi_add, arg_0, arg_1, arg_2, arg_3) g = g.compile ()
注:在调用 ti.init 的时候,传入参数 print_ir=True,可以将 IR 的 pass 优化过程打印出来,由此可以观察到某个特性是在哪一个 pass 被加入的。
整体流程 在代码从 Python 到最终 SPIRV-V 的过程中,会经过以下流程:
Frontend IR 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 kernel { $0 : for @tmp0 in range ((cast_value<i32> 0 ), (cast_value<i32> ((0 max arg[2 ] (dt=i32)) - 0 ))) block_dim =adaptive { $1 = alloca @tmp1 @tmp1 = @tmp0 $3 = alloca @tmp2 @tmp2 = @tmp1 $5 = alloca @tmp3 @tmp3 = (@tmp2 + 0 ) $7 = alloca @tmp4 @tmp4 = @tmp3 $9 = alloca @tmp5 @tmp5 = internal call composite_extract_0 (texture_kLoad (@tmp4)) $11 = alloca @tmp6 @tmp6 = internal call composite_extract_1 (texture_kLoad (@tmp4)) $13 = alloca @tmp7 @tmp7 = internal call composite_extract_2 (texture_kLoad (@tmp4)) $15 = alloca @tmp8 @tmp8 = internal call composite_extract_3 (texture_kLoad (@tmp4)) $17 = alloca @tmp9 @tmp9 = (cast_value<f32> @tmp5) $19 = alloca @tmp10 @tmp10 = (cast_value<f32> @tmp6) $21 = alloca @tmp11 @tmp11 = (cast_value<f32> @tmp7) $23 = alloca @tmp12 @tmp12 = (cast_value<f32> @tmp8) $25 = alloca @tmp13 @tmp13 = (cast_value<f32> @tmp9) $27 = alloca @tmp14 @tmp14 = (cast_value<f32> @tmp10) $29 = alloca @tmp15 @tmp15 = (cast_value<f32> @tmp11) $31 = alloca @tmp16 @tmp16 = (cast_value<f32> @tmp12) $33 = alloca @tmp17 @tmp17 = @tmp13 $35 = alloca @tmp18 @tmp18 = @tmp14 $37 = alloca @tmp19 @tmp19 = @tmp15 $39 = alloca @tmp20 @tmp20 = @tmp16 $41 = alloca @tmp21 @tmp21 = @tmp17 $43 = alloca @tmp22 @tmp22 = @tmp18 $45 = alloca @tmp23 @tmp23 = @tmp19 $47 = alloca @tmp24 @tmp24 = @tmp20 $49 = alloca @tmp25 @tmp25 = ((cast_value<f32> arg[3 ] (dt=i32)) / 255.0 ) $51 = alloca @tmp26 @tmp26 = ((cast_value<f32> arg[3 ] (dt=i32)) / 255.0 ) $53 = alloca @tmp27 @tmp27 = ((cast_value<f32> arg[3 ] (dt=i32)) / 255.0 ) $55 = alloca @tmp28 @tmp28 = ((cast_value<f32> arg[3 ] (dt=i32)) / 255.0 ) $57 = alloca @tmp29 @tmp29 = (@tmp21 + @tmp25) $59 = alloca @tmp30 @tmp30 = (@tmp22 + @tmp26) $61 = alloca @tmp31 @tmp31 = (@tmp23 + @tmp27) $63 = alloca @tmp32 @tmp32 = (@tmp24 + @tmp28) $65 = alloca @tmp33 @tmp33 = @tmp29 $67 = alloca @tmp34 @tmp34 = @tmp30 $69 = alloca @tmp35 @tmp35 = @tmp31 $71 = alloca @tmp36 @tmp36 = @tmp32 $73 = alloca @tmp37 @tmp37 = @tmp33 $75 = alloca @tmp38 @tmp38 = @tmp34 $77 = alloca @tmp39 @tmp39 = @tmp35 $79 = alloca @tmp40 @tmp40 = @tmp36 $81 = alloca @tmp41 @tmp41 = @tmp3 $83 = alloca @tmp42 @tmp42 = texture_kStore (@tmp41, @tmp37, @tmp38, @tmp39, @tmp40) } }
浅层 CHI IR 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 kernel { <i32> $0 = const 0 $1 = cast_value<i32> $0 <i32> $2 = const 0 <i32> $3 = arg[2] <i32> $4 = max $2 $3 <i32> $5 = const 0 <i32> $6 = sub $4 $5 $7 = cast_value<i32> $6 $8 : for in range($1, $7) block_dim=adaptive { <i32> $9 = loop $8 index 0 <i32> $10 = alloca $11 : local store [$10 <- $9] <i32> $12 = alloca $13 = local load [$10] $14 : local store [$12 <- $13] <i32> $15 = alloca $16 = local load [$12] <i32> $17 = const 0 <i32> $18 = add $16 $17 $19 : local store [$15 <- $18] <i32> $20 = alloca $21 = local load [$15] $22 : local store [$20 <- $21] <i32> $23 = alloca <f32> $24 = arg[0] <*Texture> $25 = $24 $26 = local load [$20] <struct> $27 = texture_kLoad($26) <i32> $28 = internal call composite_extract_0($27) $29 : local store [$23 <- $28] <i32> $30 = alloca <f32> $31 = arg[0] <*Texture> $32 = $31 $33 = local load [$20] <struct> $34 = texture_kLoad($33) <i32> $35 = internal call composite_extract_1($34) $36 : local store [$30 <- $35] <i32> $37 = alloca <f32> $38 = arg[0] <*Texture> $39 = $38 $40 = local load [$20] <struct> $41 = texture_kLoad($40) <i32> $42 = internal call composite_extract_2($41) $43 : local store [$37 <- $42] <i32> $44 = alloca <f32> $45 = arg[0] <*Texture> $46 = $45 $47 = local load [$20] <struct> $48 = texture_kLoad($47) <i32> $49 = internal call composite_extract_3($48) $50 : local store [$44 <- $49] <f32> $51 = alloca $52 = local load [$23] $53 = cast_value<f32> $52 $54 : local store [$51 <- $53] <f32> $55 = alloca $56 = local load [$30] $57 = cast_value<f32> $56 $58 : local store [$55 <- $57] <f32> $59 = alloca $60 = local load [$37] $61 = cast_value<f32> $60 $62 : local store [$59 <- $61] <f32> $63 = alloca $64 = local load [$44] $65 = cast_value<f32> $64 $66 : local store [$63 <- $65] <f32> $67 = alloca $68 = local load [$51] $69 = cast_value<f32> $68 $70 : local store [$67 <- $69] <f32> $71 = alloca $72 = local load [$55] $73 = cast_value<f32> $72 $74 : local store [$71 <- $73] <f32> $75 = alloca $76 = local load [$59] $77 = cast_value<f32> $76 $78 : local store [$75 <- $77] <f32> $79 = alloca $80 = local load [$63] $81 = cast_value<f32> $80 $82 : local store [$79 <- $81] <f32> $83 = alloca $84 = local load [$67] $85 : local store [$83 <- $84] <f32> $86 = alloca $87 = local load [$71] $88 : local store [$86 <- $87] <f32> $89 = alloca $90 = local load [$75] $91 : local store [$89 <- $90] <f32> $92 = alloca $93 = local load [$79] $94 : local store [$92 <- $93] <f32> $95 = alloca $96 = local load [$83] $97 : local store [$95 <- $96] <f32> $98 = alloca $99 = local load [$86] $100 : local store [$98 <- $99] <f32> $101 = alloca $102 = local load [$89] $103 : local store [$101 <- $102] <f32> $104 = alloca $105 = local load [$92] $106 : local store [$104 <- $105] <f32> $107 = alloca <i32> $108 = arg[3] $109 = cast_value<f32> $108 <f32> $110 = const 255.0 <f32> $111 = truediv $109 $110 $112 : local store [$107 <- $111] <f32> $113 = alloca <i32> $114 = arg[3] $115 = cast_value<f32> $114 <f32> $116 = const 255.0 <f32> $117 = truediv $115 $116 $118 : local store [$113 <- $117] <f32> $119 = alloca <i32> $120 = arg[3] $121 = cast_value<f32> $120 <f32> $122 = const 255.0 <f32> $123 = truediv $121 $122 $124 : local store [$119 <- $123] <f32> $125 = alloca <i32> $126 = arg[3] $127 = cast_value<f32> $126 <f32> $128 = const 255.0 <f32> $129 = truediv $127 $128 $130 : local store [$125 <- $129] <f32> $131 = alloca $132 = local load [$95] $133 = local load [$107] <f32> $134 = add $132 $133 $135 : local store [$131 <- $134] <f32> $136 = alloca $137 = local load [$98] $138 = local load [$113] <f32> $139 = add $137 $138 $140 : local store [$136 <- $139] <f32> $141 = alloca $142 = local load [$101] $143 = local load [$119] <f32> $144 = add $142 $143 $145 : local store [$141 <- $144] <f32> $146 = alloca $147 = local load [$104] $148 = local load [$125] <f32> $149 = add $147 $148 $150 : local store [$146 <- $149] <f32> $151 = alloca $152 = local load [$131] $153 : local store [$151 <- $152] <f32> $154 = alloca $155 = local load [$136] $156 : local store [$154 <- $155] <f32> $157 = alloca $158 = local load [$141] $159 : local store [$157 <- $158] <f32> $160 = alloca $161 = local load [$146] $162 : local store [$160 <- $161] <f32> $163 = alloca $164 = local load [$151] $165 : local store [$163 <- $164] <f32> $166 = alloca $167 = local load [$154] $168 : local store [$166 <- $167] <f32> $169 = alloca $170 = local load [$157] $171 : local store [$169 <- $170] <f32> $172 = alloca $173 = local load [$160] $174 : local store [$172 <- $173] <i32> $175 = alloca $176 = local load [$15] $177 : local store [$175 <- $176] $178 = alloca <f32> $179 = arg[1] <*Texture> $180 = $179 $181 = local load [$175] $182 = local load [$163] $183 = local load [$166] $184 = local load [$169] $185 = local load [$172] <struct> $186 = texture_kStore($181, $182, $183, $184, $185) $187 : local store [$178 <- $186] } }
深层 CHI IR 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 kernel { $0 = offloaded body { <i32> $1 = const 0 <i32> $2 = arg[2] <i32> $3 = max $1 $2 <*i32> $4 = global tmp var (offset = 0 B) $5 : global store [$4 <- $3] } $6 = offloaded range_for(0, tmp(offset=0B)) grid_dim=0 block_dim=128 body { <i32> $7 = loop $6 index 0 <*f32> $8 = arg[0] <*Texture> $9 = $8 <struct> $10 = texture_kLoad($7) <i32> $11 = internal call composite_extract_0($10) <*Texture> $12 = $8 <struct> $13 = texture_kLoad($7) <i32> $14 = internal call composite_extract_1($13) <*Texture> $15 = $8 <struct> $16 = texture_kLoad($7) <i32> $17 = internal call composite_extract_2($16) <*Texture> $18 = $8 <struct> $19 = texture_kLoad($7) <i32> $20 = internal call composite_extract_3($19) <f32> $21 = cast_value<f32> $11 <f32> $22 = cast_value<f32> $14 <f32> $23 = cast_value<f32> $17 <f32> $24 = cast_value<f32> $20 <i32> $25 = arg[3] <f32> $26 = cast_value<f32> $25 <f32> $27 = const 0.003921569 <f32> $28 = mul $26 $27 <f32> $29 = add $21 $28 <f32> $30 = add $22 $28 <f32> $31 = add $23 $28 <f32> $32 = add $24 $28 <*f32> $33 = arg[1] <*Texture> $34 = $33 <struct> $35 = texture_kStore($7, $29, $30, $31, $32) } }
SPIR-V 为了方便阅读,将 SPIR-V 反编译成 GLSL。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 layout(set = 0, binding = 2, std430) buffer global_tmps_buffer_u32_ptr { uint _m0[]; } global_tmps_buffer_u32; void main() { if (gl_GlobalInvocationID.x == 0u) { global_tmps_buffer_u32._m0[0] = uint(max(0, args._m2)); } } layout(set = 0, binding = 2, std430) buffer global_tmps_buffer_i32_ptr { int _m0[]; } global_tmps_buffer_i32; layout(set = 0, binding = 3, rgba8) uniform readonly image1D tmp18_unknown; layout(set = 0, binding = 4, rgba8) uniform writeonly image1D tmp34_unknown; void main() { int begin_ = int(gl_GlobalInvocationID.x) + 0; int end_ = (global_tmps_buffer_i32._m0[0 >> 2] - 0) + 0; int total_invocs = int(gl_NumWorkGroups.x * 128u); for (int tmp7_i32 = begin_; tmp7_i32 < end_; tmp7_i32 += total_invocs) { float tmp28_f32 = float(args._m3) * 0.0039215688593685626983642578125; imageStore(tmp34_unknown, tmp7_i32, vec4(imageLoad(tmp18_unknown, tmp7_i32).x + tmp28_f32, imageLoad(tmp18_unknown, tmp7_i32).y + tmp28_f32, imageLoad(tmp18_unknown, tmp7_i32).z + tmp28_f32, imageLoad(tmp18_unknown, tmp7_i32).w + tmp28_f32)); } }
创建 graph 创建 graph 的相关代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 class GraphBuilder : def __init__ (self ): self._graph_builder = _ti_core.GraphBuilder() def dispatch (self, kernel_fn, *args ): kernel_cpp = gen_cpp_kernel(kernel_fn, args) unzipped_args = flatten_args(args) self._graph_builder.dispatch(kernel_cpp, unzipped_args) def compile (self ): return Graph(self._graph_builder.compile ())
可以看出,Python kernel 会先通过 gen_cpp_kernel 函数转成 C++ 形式的 kernel,然后送进 GraphBuilder::dispatch 中。
Python AST -> Frontend IR (C++) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 def gen_cpp_kernel (kernel_fn, args ): kernel = kernel_fn._primal assert isinstance (kernel, kernel_impl.Kernel) injected_args = produce_injected_args(kernel, symbolic_args=args) key = kernel.ensure_compiled(*injected_args) return kernel.compiled_kernels[key] class Kernel : ... def ensure_compiled (self, *args ): instance_id, arg_features = self.mapper.lookup(args) key = (self.func, instance_id, self.autodiff_mode) self.materialize(key=key, args=args, arg_features=arg_features) return key def materialize (self, key=None , args=None , arg_features=None ): ... tree, ctx = _get_tree_and_ctx( self, args=args, excluded_parameters=self.template_slot_locations, arg_features=arg_features) def taichi_ast_generator (kernel_cxx ): ... ctx.ast_builder = kernel_cxx.ast_builder() transform_tree(tree, ctx) ... taichi_kernel = impl.get_runtime().prog.create_kernel( taichi_ast_generator, kernel_name, self.autodiff_mode) ... def _get_tree_and_ctx (self, excluded_parameters=( is_kernel=True , arg_features=None , args=None , ast_builder=None , is_real_function=False ): file = oinspect.getsourcefile(self.func) src, start_lineno = oinspect.getsourcelines(self.func) src = [textwrap.fill(line, tabsize=4 , width=9999 ) for line in src] tree = ast.parse(textwrap.dedent("\n" .join(src))) ...
Frontend IR 的主要作用就是把 Python AST 以 C++ 对象的形式呈现,这样才能在 C++ 中做各种编译优化。上述代码中的变量 kernel_cxx 的类型对应到 C++ 中就是 taichi::lang::Kernel。函数 transform_tree 对 IR 的转换如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def transform_tree (tree, ctx: ASTTransformerContext ): ASTTransformer()(ctx, tree) return ctx.return_data class ASTTransformer (Builder ): ... class Builder : def __call__ (self, ctx, node ): method = getattr (self, 'build_' + node.__class__.__name__, None ) ... return method(ctx, node)
从这段代码可以看出对于传进来的节点都会调用对应的 build 函数,这个函数的第一次调用便是 build_Module:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class ASTTransformer (Builder ): ... @staticmethod def build_Module (ctx, node ): with ctx.variable_scope_guard(): for stmt in node.body: build_stmt(ctx, stmt) return None ...
再来看一个 build_While 的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ASTTransformer (Builder ): ... @staticmethod def build_While (ctx, node ): if node.orelse: raise TaichiSyntaxError("'else' clause for 'while' not supported in Taichi kernels" ) with ctx.loop_scope_guard(): ctx.ast_builder.begin_frontend_while(expr.Expr(1 , dtype=primitive_types.i32).ptr) while_cond = build_stmt(ctx, node.test) impl.begin_frontend_if(ctx.ast_builder, while_cond) ctx.ast_builder.begin_frontend_if_true() ctx.ast_builder.pop_scope() ctx.ast_builder.begin_frontend_if_false() ctx.ast_builder.insert_break_stmt() ctx.ast_builder.pop_scope() build_stmts(ctx, node.body) ctx.ast_builder.pop_scope() return None ...
这里 ctx 的类型对应到 C++ 中就是类 FrontendContext。在这个函数中,可以看到 Python AST 中的相关逻辑被转换到了 ctx 中。后续的代码生成将基于这个对象进行。
Dispatch Python 类 GraphBuilder 本质上就是 C++ 类 GraphBuilder 的包装,成员函数也只是直接转发了 C++ 类的同名成员函数。相关 C++ 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Node { public : ... virtual void compile (std::vector<aot::CompiledDispatch> &compiled_dispatches) 0 ; }; class Dispatch : public Node { public : ... void compile (std::vector<aot::CompiledDispatch> &compiled_dispatches) override }; class Sequential : public Node { public : ... void compile (std::vector<aot::CompiledDispatch> &compiled_dispatches) override }; void GraphBuilder::dispatch (Kernel *kernel, const std::vector<aot::Arg> &args) seq ()->dispatch (kernel, args); } void Sequential::dispatch (Kernel *kernel, const std::vector<aot::Arg> &args) Node *n = owning_graph_->new_dispatch_node (kernel, args); sequence_.push_back (n); }
在上述代码中,所有未编译的 kernel 都会作为一个 node 被放到一个 std::vector<Node*> 中。
编译 graph 编译 graph 的相关代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 std::unique_ptr<aot::CompiledGraph> GraphBuilder::compile () { std::vector<aot::CompiledDispatch> dispatches; seq ()->compile (dispatches); aot::CompiledGraph graph{dispatches, all_args_}; return std::make_unique <aot::CompiledGraph>(std::move (graph)); } void Sequential::compile (std::vector<aot::CompiledDispatch> &compiled_dispatches) for (Node *n : sequence_) { n->compile (compiled_dispatches); } } void Dispatch::compile (std::vector<aot::CompiledDispatch> &compiled_dispatches) if (kernel_->compiled_aot_kernel () == nullptr ) { kernel_->compile_to_aot_kernel (); } aot::CompiledDispatch dispatch{kernel_->get_name (), symbolic_args_, kernel_->compiled_aot_kernel ()}; compiled_dispatches.push_back (std::move (dispatch)); }
虽然在几个数据类型之间绕来绕去,但是最终函数回归到了 Dispatch::compile 这个函数中,最终真正执行编译操作的则是 Kernel::compile_to_aot_kernel 函数:
1 2 3 4 void Kernel::compile_to_aot_kernel () compiled_aot_kernel_ = program->make_aot_kernel (*this ); }
从这里开始,就会区分不同的编译 backend 了。
Vulkan backend 上面代码中的 program 的类型 Program 其实是个基类,对于 vulkan backend,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 std::unique_ptr<aot::Kernel> VulkanProgramImpl::make_aot_kernel (Kernel &kernel) { auto params = get_cache_manager ()->load_or_compile (config, &kernel); return std::make_unique <gfx::KernelImpl>(vulkan_runtime_.get (), std::move (params)); } CompiledKernelData CacheManager::load_or_compile (CompileConfig *config, Kernel *kernel) if (kernel->is_evaluator) { spirv::lower (kernel); return gfx::run_codegen (kernel, runtime_->get_ti_device (), compiled_structs_); } ... }
在 CacheManager::load_or_compile 函数中,首先将 kernel 进行 lower 操作,然后进行 SPIR-V 代码生成。
Frontend IR -> CHI IR & CHI IR pass 优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void lower (Kernel *kernel) auto &config = kernel->program->this_thread_config (); config.demote_dense_struct_fors = true ; irpass::compile_to_executable (kernel->ir.get (), config, kernel, kernel->autodiff_mode, false , config.print_ir, true , false ); } void compile_to_executable (IRNode *ir, const CompileConfig &config, Kernel *kernel, AutodiffMode autodiff_mode, bool ad_use_stack, bool verbose, bool lower_global_access, bool make_thread_local, bool make_block_local, bool start_from_ast) TI_AUTO_PROF; compile_to_offloads (ir, config, kernel, verbose, autodiff_mode, ad_use_stack, start_from_ast); offload_to_executable ( ir, config, kernel, verbose, autodiff_mode == AutodiffMode::kReverse && ad_use_stack, lower_global_access, make_thread_local, make_block_local); }
在 pass 优化中,类型为 IRNode 的对象 ir 会贯穿整个流程。在 taichi::lang::Kernel 的 init 函数中,FrontendContext 中的数据会被转移到 ir 中,FrontendContext 中的数据则是从 Python 中由 Python AST 转换来的。
在 compile_to_offloads 函数中,会进行一系列的 pass,对 CHI IR 进行优化:https://github.com/taichi-dev/taichi/blob/v1.2.0/taichi/transforms/compile_to_offloads.cpp#L32。
在 offload_to_executable 函数中,也会进行另外一系列的 pass,对 CHI IR 进行优化:https://github.com/taichi-dev/taichi/blob/v1.2.0/taichi/transforms/compile_to_offloads.cpp#L164。
我们以 demote atomics pass 为例过一下流程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 bool demote_atomics (IRNode *root, const CompileConfig &config) TI_AUTO_PROF; bool modified = DemoteAtomics::run (root); type_check (root, config); return modified; } class DemoteAtomics : public BasicStmtVisitor { ... static bool run (IRNode *node) DemoteAtomics demoter; bool modified = false ; while (true ) { node->accept (&demoter); if (demoter.modifier.modify_ir ()) { modified = true ; } else { break ; } } return modified; } };
在 pass 中,我们经常会看到诸如node->accept(&demoter)的代码,其含义可等同于demoter.visit(node)。上述代码执行后,就会递归遍历这棵语法树,每个节点都是一个 stmt。每种类型的 stmt 都会有对应的处理函数,我们以 AtomicOpStmt 看一下这个过程是怎样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class DemoteAtomics : public BasicStmtVisitor { ... void visit (AtomicOpStmt *stmt) override ... if (demote) { auto bin_type = atomic_to_binary_op_type (stmt->op_type); auto ptr = stmt->dest; auto val = stmt->val; auto new_stmts = VecStatement (); Stmt *load; if (is_local) { load = new_stmts.push_back <LocalLoadStmt>(ptr); auto bin = new_stmts.push_back <BinaryOpStmt>(bin_type, load, val); new_stmts.push_back <LocalStoreStmt>(ptr, bin); } else { load = new_stmts.push_back <GlobalLoadStmt>(ptr); auto bin = new_stmts.push_back <BinaryOpStmt>(bin_type, load, val); new_stmts.push_back <GlobalStoreStmt>(ptr, bin); } stmt->replace_usages_with (load); modifier.replace_with (stmt, std::move (new_stmts), false ); } } };
在上面这段代码中,我们可以看到一个二元运算符被分解成 load、运算、store 三个原子操作。
SPIR-V 代码生成 1 2 3 4 5 6 7 8 9 10 GfxRuntime::RegisterParams run_codegen ( Kernel *kernel, Device *device, const std::vector<CompiledSNodeStructs> &compiled_structs) ... spirv::KernelCodegen codegen (params) ; codegen.run (res.kernel_attribs, res.task_spirv_source_codes); ... }
在 spirv::KernelCodegen 的构造函数中,会将 SPIR-V 官方工具中的一些编译器 pass 注册进去:https://github.com/taichi-dev/taichi/blob/v1.2.0/taichi/codegen/spirv/spirv_codegen.cpp#L2439。
接下来就是进行 SPIR-V 代码生成了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void KernelCodegen::run (TaichiKernelAttributes &kernel_attribs, std::vector<std::vector<uint32_t >> &generated_spirv) auto *root = params_.kernel->ir->as <Block>(); auto &tasks = root->statements; for (int i = 0 ; i < tasks.size (); ++i) { ... TaskCodegen cgen (tp) ; auto task_res = cgen.run (); std::vector<uint32_t > optimized_spv (task_res.spirv_code) ; spirv_opt_->Run (optimized_spv.data (), optimized_spv.size (), &optimized_spv, spirv_opt_options_) TI_TRACE ("SPIRV-Tools-opt: binary size, before={}, after={}" , task_res.spirv_code.size (), optimized_spv.size ()); ... } ... }
上述代码会对所有的 task 进行代码生成,然后进行代码优化。这里的 task 是指 offload 的单元,可以简单理解成串行结构和并行结构分开进行代码生成。代码优化则是调用了 SPIR-V 的官方 API 进行优化。
下面是代码生成的具体逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Result run () { ... if (task_ir_->task_type == OffloadedTaskType::serial) { generate_serial_kernel (task_ir_); } else if (task_ir_->task_type == OffloadedTaskType::range_for) { generate_range_for_kernel (task_ir_); } else if (task_ir_->task_type == OffloadedTaskType::listgen) { generate_listgen_kernel (task_ir_); } else if (task_ir_->task_type == OffloadedTaskType::struct_for) { generate_struct_for_kernel (task_ir_); } else { TI_ERROR ("Unsupported offload type={} on SPIR-V codegen" , task_ir_->task_name ()); } ... }
串行结构(serial_kernel)代码生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void generate_serial_kernel (OffloadedStmt *stmt) task_attribs_.name = task_name_; task_attribs_.task_type = OffloadedTaskType::serial; task_attribs_.advisory_total_num_threads = 1 ; task_attribs_.advisory_num_threads_per_group = 1 ; ir_->start_function (kernel_function_); spirv::Value cond = ir_->eq (ir_->get_global_invocation_id (0 ), ir_->uint_immediate_number ( ir_->u32_type (), 0 )); spirv::Label then_label = ir_->new_label (); spirv::Label merge_label = ir_->new_label (); kernel_return_label_ = merge_label; ir_->make_inst (spv::OpSelectionMerge, merge_label, spv::SelectionControlMaskNone); ir_->make_inst (spv::OpBranchConditional, cond, then_label, merge_label); ir_->start_label (then_label); stmt->body->accept (this ); ir_->make_inst (spv::OpBranch, merge_label); ir_->start_label (merge_label); ir_->make_inst (spv::OpReturn); ir_->make_inst (spv::OpFunctionEnd); ... }
对于串行结构,每个 block 中的线程数和总的线程数都被设为 1。接下来用到了 taichi 自己实现的一个类 IRBuilder(即代码中的 ir_),功能上类似 LLVM 中的 Module,都是用来构建结构化 IR 的。通过 IRBuilder,代码构建了一个 if-else,起作用是判断当前线程是否为 0 号线程。整个函数体的代码生成将由 accept 函数完成。
accept 函数代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Block : public IRNode { ... void accept (IRVisitor *visitor) override visitor->visit (this ); } }; void visit (Block *stmt) override for (auto &s : stmt->statements) { if (offload_loop_motion_.find (s.get ()) == offload_loop_motion_.end ()) { s->accept (this ); } } }
通过上面这两段代码可以看出,stmt->body->accept(this);即对整个 block 中的所有 stmt 做了代码生成。对于不同的 stmt,则可以在 taichi/codegen/spirv/spirv_codegen.cpp 中找到对应的 visit 函数,这样就可以看到其代码生成细节。
并行结构(range_for_kernel)代码生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 void generate_range_for_kernel (OffloadedStmt *stmt) ... ir_->start_function (kernel_function_); const std::string total_elems_name ("total_elems" ) spirv::Value total_elems; spirv::Value begin_expr_value; if (range_for_attribs.const_range ()) { const int num_elems = range_for_attribs.end - range_for_attribs.begin; begin_expr_value = ir_->int_immediate_number (ir_->i32_type (), stmt->begin_value, false ); total_elems = ir_->int_immediate_number (ir_->i32_type (), num_elems, false ); task_attribs_.advisory_total_num_threads = num_elems; } else { spirv::Value end_expr_value; if (stmt->end_stmt) { TI_ASSERT (stmt->const_begin); begin_expr_value = ir_->int_immediate_number (ir_->i32_type (), stmt->begin_value, false ); gen_array_range (stmt->end_stmt); end_expr_value = ir_->query_value (stmt->end_stmt->raw_name ()); } else { if (!stmt->const_begin) { spirv::Value begin_idx = ir_->make_value ( spv::OpShiftRightArithmetic, ir_->i32_type (), ir_->int_immediate_number (ir_->i32_type (), stmt->begin_offset), ir_->int_immediate_number (ir_->i32_type (), 2 )); begin_expr_value = ir_->load_variable ( ir_->struct_array_access ( ir_->i32_type (), get_buffer_value (BufferType::GlobalTmps, PrimitiveType::i32), begin_idx), ir_->i32_type ()); } else { begin_expr_value = ir_->int_immediate_number ( ir_->i32_type (), stmt->begin_value, false ); } if (!stmt->const_end) { spirv::Value end_idx = ir_->make_value ( spv::OpShiftRightArithmetic, ir_->i32_type (), ir_->int_immediate_number (ir_->i32_type (), stmt->end_offset), ir_->int_immediate_number (ir_->i32_type (), 2 )); end_expr_value = ir_->load_variable ( ir_->struct_array_access ( ir_->i32_type (), get_buffer_value (BufferType::GlobalTmps, PrimitiveType::i32), end_idx), ir_->i32_type ()); } else { end_expr_value = ir_->int_immediate_number (ir_->i32_type (), stmt->end_value, true ); } } total_elems = ir_->sub (end_expr_value, begin_expr_value); task_attribs_.advisory_total_num_threads = kMaxNumThreadsGridStrideLoop; } task_attribs_.advisory_num_threads_per_group = stmt->block_dim; ir_->debug_name (spv::OpName, begin_expr_value, "begin_expr_value" ); ir_->debug_name (spv::OpName, total_elems, total_elems_name); spirv::Value begin_ = ir_->add (ir_->cast (ir_->i32_type (), ir_->get_global_invocation_id (0 )), begin_expr_value); ir_->debug_name (spv::OpName, begin_, "begin_" ); spirv::Value end_ = ir_->add (total_elems, begin_expr_value); ir_->debug_name (spv::OpName, end_, "end_" ); const std::string total_invocs_name = "total_invocs" ; spirv::Value total_invocs = ir_->cast ( ir_->i32_type (), ir_->mul (ir_->get_num_work_groups (0 ), ir_->uint_immediate_number ( ir_->u32_type (), task_attribs_.advisory_num_threads_per_group, true ))); ir_->debug_name (spv::OpName, total_invocs, total_invocs_name); ... }
从上面的代码可以看出,并行结构的代码生成并没有比串行结构复杂多少,区别在两点:
多了循环条件的生成
多了循环步长 total_invocs 的生成:total_invocs = num_work_groups * num_threads_per_group
LLVM backend 上面代码中的 program 的类型 Program 其实是个基类,对于 LLVM backend,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 std::unique_ptr<aot::Kernel> LlvmProgramImpl::make_aot_kernel (Kernel &kernel) { auto compiled_fn = this ->compile (&kernel, nullptr ); ... return std::make_unique <llvm_aot::KernelImpl>(compiled_fn, std::move (compiled_kernel)); } FunctionType LlvmProgramImpl::compile (Kernel *kernel, OffloadedStmt *offloaded) { auto codegen = KernelCodeGen::create (kernel->arch, kernel, offloaded); return codegen->compile_to_function (); }
这里又进行了一次分化,区分了 CPU codegen 和 CUDA codegen,但是很快就又进入了公共逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 FunctionType KernelCodeGenCUDA::compile_to_function () { TI_AUTO_PROF auto *llvm_prog = get_llvm_program (prog); auto *tlctx = llvm_prog->get_llvm_context (kernel->arch); CUDAModuleToFunctionConverter converter{tlctx, llvm_prog->get_runtime_executor ()}; return converter.convert (this ->kernel, compile_kernel_to_module ()); } FunctionType KernelCodeGenCPU::compile_to_function () { TI_AUTO_PROF; auto *llvm_prog = get_llvm_program (prog); auto *tlctx = llvm_prog->get_llvm_context (kernel->arch); CPUModuleToFunctionConverter converter (tlctx, get_llvm_program(prog)->get_runtime_executor()) ; return converter.convert (kernel, compile_kernel_to_module ()); } LLVMCompiledKernel KernelCodeGen::compile_kernel_to_module () { ... if (!kernel->lowered ()) { kernel->lower (false ); } auto block = dynamic_cast <Block *>(kernel->ir.get ()); auto &offloads = block->statements; std::vector<std::unique_ptr<LLVMCompiledTask>> data (offloads.size ()); for (int i = 0 ; i < offloads.size (); i++) { ... auto new_data = this ->compile_task (nullptr , offload->as <OffloadedStmt>()); data[i] = std::make_unique <LLVMCompiledTask>(std::move (new_data)); } auto linked = tlctx->link_compiled_tasks (std::move (data)); ... return linked; }
可以看出,函数 compile_kernel_to_module 做了以下几件事:
lower:Frontend IR -> CHI IR & CHI IR pass 优化
compile_task:LLVM 代码生成
link_compiled_tasks:链接 LLVM module
Frontend IR -> CHI IR & CHI IR pass 优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void Kernel::lower (bool to_executable) ... if (config.print_preprocessed_ir) { TI_INFO ("[{}] {}:" , get_name (), "Preprocessed IR" ); std::cout << std::flush; irpass::re_id (ir.get ()); irpass::print (ir.get ()); std::cout << std::flush; } if (to_executable) { irpass::compile_to_executable ( ir.get (), config, this , autodiff_mode, true , verbose, to_executable, config.make_thread_local, is_extension_supported (config.arch, Extension::bls) && config.make_block_local, ir_is_ast_); } else { irpass::compile_to_offloads (ir.get (), config, this , verbose, autodiff_mode, true , ir_is_ast_); } lowered_ = true ; }
这段逻辑和 vulkan backend 中的 lower 作用是一样的,这里就不重复解读了。
LLVM 代码生成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 LLVMCompiledTask KernelCodeGenCUDA::compile_task ( std::unique_ptr<llvm::Module> &&module , OffloadedStmt *stmt) TaskCodeGenCUDA gen (kernel, stmt) ; return gen.run_compilation (); } LLVMCompiledTask KernelCodeGenCPU::compile_task ( std::unique_ptr<llvm::Module> &&module , OffloadedStmt *stmt) TaskCodeGenCPU gen (kernel, stmt) ; return gen.run_compilation (); } LLVMCompiledTask TaskCodeGenLLVM::run_compilation () { ... emit_to_module (); ... return {std::move (offloaded_tasks), std::move (module ), std::move (used_tree_ids), std::move (struct_for_tls_sizes)}; } void TaskCodeGenLLVM::emit_to_module () TI_AUTO_PROF ir->accept (this ); } class Block : public IRNode { ... void accept (IRVisitor *visitor) override visitor->visit (this ); } }; void TaskCodeGenLLVM::visit (Block *stmt_list) for (auto &stmt : stmt_list->statements) { stmt->accept (this ); if (returned) { break ; } } }
通过上面这段代码可以看出,整个函数体的代码生成将由 accept 函数完成。代码生成的入口则是 Block 的 visit 函数,然后针对每条 stmt 做了 accept。对于不同的 stmt,则可以在 taichi/codegen/llvm/codegen_llvm.cpp 中找到对应的 visit 函数,这样就可以看到其代码生成细节。
在众多 stmt 中,有一个特殊 stmt 比较特殊,就是 OffloadedStmt。offload 可以理解为子 block,也是一系列代码的集合。对于不同的 backend,在 offload 这一层就有区分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 void visit (OffloadedStmt *stmt) override ... init_offloaded_task_function (stmt); if (stmt->task_type == Type::serial) { stmt->body->accept (this ); } else if (stmt->task_type == Type::range_for) { create_offload_range_for (stmt); } else if (stmt->task_type == Type::struct_for) { create_offload_struct_for (stmt, true ); } else if (stmt->task_type == Type::mesh_for) { create_offload_mesh_for (stmt); } else if (stmt->task_type == Type::listgen) { emit_list_gen (stmt); } else { TI_NOT_IMPLEMENTED } ... } void visit (OffloadedStmt *stmt) override { ... if (stmt->task_type == Type::serial) { stmt->body->accept (this ); } else if (stmt->task_type == Type::range_for) { create_offload_range_for (stmt); } else if (stmt->task_type == Type::mesh_for) { create_offload_mesh_for (stmt); } else if (stmt->task_type == Type::struct_for) { stmt->block_dim = std::min (stmt->snode->parent->max_num_elements (), (int64)stmt->block_dim); create_offload_struct_for (stmt); } else if (stmt->task_type == Type::listgen) { emit_list_gen (stmt); } else if (stmt->task_type == Type::gc) { emit_gc (stmt); } else { TI_NOT_IMPLEMENTED } ... }
可以看到,对于不同的 task,会分别调用 TaskCodeGenCPU 和 TaskCodeGenCUDA 中的同名函数。
串行结构(serial_kernel)代码生成 CPU backend 和 CUDA backend 在串行结构的代码生成上是一致的,都是直接对 stmt 进行 accept:
1 stmt->body->accept (this );
并行结构(range_for_kernel)代码生成 CUDA
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 void create_offload_range_for (OffloadedStmt *stmt) override ... llvm::Function *body; { auto guard = get_function_creation_guard ( {llvm::PointerType::get (get_runtime_type ("RuntimeContext" ), 0 ), get_tls_buffer_type (), tlctx->get_data_type <int >()}); auto loop_var = create_entry_block_alloca (PrimitiveType::i32); loop_vars_llvm[stmt].push_back (loop_var); builder->CreateStore (get_arg (2 ), loop_var); stmt->body->accept (this ); body = guard.body; } ... auto [begin, end] = get_range_for_bounds (stmt); call ("gpu_parallel_range_for" , get_arg (0 ), begin, end, tls_prologue, body, epilogue, tlctx->get_constant (stmt->tls_size)); } template <typename ... Args>llvm::Value *call (const std::string &func_name, Args &&...args) { auto func = get_func (func_name); auto arglist = std::vector <llvm::Value *>({ptr, args...}); check_func_call_signature (func->getFunctionType (), func->getName (), arglist, builder); return builder->CreateCall (func, std::move (arglist)); } void gpu_parallel_range_for (RuntimeContext *context, int begin, int end, range_for_xlogue prologue, RangeForTaskFunc *func, range_for_xlogue epilogue, const std::size_t tls_size) int idx = thread_idx () + block_dim () * block_idx () + begin; alignas (8 ) char tls_buffer[tls_size]; auto tls_ptr = &tls_buffer[0 ]; while (idx < end) { func (context, tls_ptr, idx); idx += block_dim () * grid_dim (); } }
在函数 create_offload_range_for 中,首先将循环体的代码生成,然后将生成的循环体以函数指针的形式传入函数 gpu_parallel_range_for 中(这个函数在运行期才会调用)。函数 gpu_parallel_range_for 的作用则是创建循环条件然后运行循环体。值得一提的是,函数 gpu_parallel_range_for 是预先实现好的,这里会将其转成 LLVM IR 然后和通过 CHI IR 生成的 LLVM IR 合并。
CPU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 void create_offload_range_for (OffloadedStmt *stmt) override ... llvm::Function *body; { auto guard = get_function_creation_guard ( {llvm::PointerType::get (get_runtime_type ("RuntimeContext" ), 0 ), llvm::Type::getInt8PtrTy (*llvm_context), tlctx->get_data_type <int >()}); auto loop_var = create_entry_block_alloca (PrimitiveType::i32); loop_vars_llvm[stmt].push_back (loop_var); builder->CreateStore (get_arg (2 ), loop_var); stmt->body->accept (this ); body = guard.body; } auto [begin, end] = get_range_for_bounds (stmt); if (prog->this_thread_config ().cpu_block_dim_adaptive) { int num_items = (stmt->end_value - stmt->begin_value) / std::abs (step); int num_threads = stmt->num_cpu_threads; int items_per_thread = std::max (1 , num_items / (num_threads * 32 )); stmt->block_dim = std::min (1024 , std::max (512 , items_per_thread)); } call ("cpu_parallel_range_for" , get_arg (0 ), tlctx->get_constant (stmt->num_cpu_threads), begin, end, tlctx->get_constant (step), tlctx->get_constant (stmt->block_dim), tls_prologue, body, epilogue, tlctx->get_constant (stmt->tls_size)); } template <typename ... Args>llvm::Value *call (const std::string &func_name, Args &&...args) { auto func = get_func (func_name); auto arglist = std::vector <llvm::Value *>({ptr, args...}); check_func_call_signature (func->getFunctionType (), func->getName (), arglist, builder); return builder->CreateCall (func, std::move (arglist)); } void cpu_parallel_range_for (RuntimeContext *context, int num_threads, int begin, int end, int step, int block_dim, range_for_xlogue prologue, RangeForTaskFunc *body, range_for_xlogue epilogue, std::size_t tls_size) ... runtime->parallel_for (runtime->thread_pool, (end - begin + block_dim - 1 ) / block_dim, num_threads, &ctx, cpu_parallel_range_for_task); }
和前面 CUDA 代码生成的逻辑非常相近,这里不再重复解读了。有两点需要注意下:
函数 create_offload_range_for 中多了自适应线程数的计算
函数 parallel_for 的实际定义在 taichi/system/threading.h,是一个基于线程池的并行函数
链接 LLVM module 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 LLVMCompiledKernel TaichiLLVMContext::link_compiled_tasks (std::vector<std::unique_ptr<LLVMCompiledTask>> data_list) { LLVMCompiledKernel linked; std::unordered_set<int > used_tree_ids; std::unordered_set<int > tls_sizes; std::unordered_set<std::string> offloaded_names; auto mod = new_module ("kernel" , linking_context_data->llvm_context); llvm::Linker linker (*mod) ; for (auto &datum : data_list) { for (auto tree_id : datum->used_tree_ids) { used_tree_ids.insert (tree_id); } for (auto tls_size : datum->struct_for_tls_sizes) { tls_sizes.insert (tls_size); } for (auto &task : datum->tasks) { offloaded_names.insert (task.name); linked.tasks.push_back (std::move (task)); } linker.linkInModule (clone_module_to_context (datum->module .get (), linking_context_data->llvm_context)); } for (auto tree_id : used_tree_ids) { linker.linkInModule (llvm::CloneModule (*linking_context_data->struct_modules[tree_id]), llvm::Linker::LinkOnlyNeeded | llvm::Linker::OverrideFromSrc); } auto runtime_module = llvm::CloneModule (*linking_context_data->runtime_module); for (auto tls_size : tls_sizes) { add_struct_for_func (runtime_module.get (), tls_size); } linker.linkInModule (std::move (runtime_module), llvm::Linker::LinkOnlyNeeded | llvm::Linker::OverrideFromSrc); eliminate_unused_functions (mod.get (), [&](std::string func_name) -> bool { return offloaded_names.count (func_name); }); linked.module = std::move (mod); return linked; }
上面这段代码就是调用 LLVM API 将多个 LLVMCompiledTask 链接在一起,并且链接其依赖和 taichi runtime。
Q & A Q:上面的 demo 为何会生成两个 kernel?
A:获取标量参数的操作从逻辑上不属于循环体,所以在优化中被从循环体中单拎出来。单拎出来后,就分成了 for 和非 for 两部分逻辑,会被 offload 成不同的 task。两个 task 如果涉及到数据交互,就会通过全局变量来通信,全局变量 global_tmp_buffer 也是在 offload 这一步出现的。
Q:为什么基于 ndarray 的 case 不会产生两个 kernel?
A:offload pass 针对获取 ndarray shape 的操作做了特殊处理:Stmt involving simple arithmetic of ExternalTensorShapeAlongAxisStmt shouldn’t be saved in global tmp, just clone them to each shader separately,代码见 https://github.com/taichi-dev/taichi/blob/v1.2.0/taichi/transforms/offload.cpp#L16。
Q:为什么要多一层 Frontend IR?
A:从代码层面讲,Frontend IR 并不存在一个与之对应的类。Frontend IR 和浅层深层 IR 一样,都是数据结构 IRNode,只是用这些名字来表示 IR 优化的不同阶段。确切的说,Frontend IR 和 CHI IR 是同一个 stmt 集合下不同的子集,且二者有交集。